経済・報道・医療など、あらゆる産業にてデータサイエンティストの需要が高まる一方、日本の多くの大学では教育が不十分であり、社会に通用する人材の育成が急務となっています。
このような背景から、2016年1月に産官学の要請を受けた「第5期科学技術基本計画」が閣議決定され、同年12月に政府は日本のデータサイエンス教育を変革するための拠点校を制定しました。
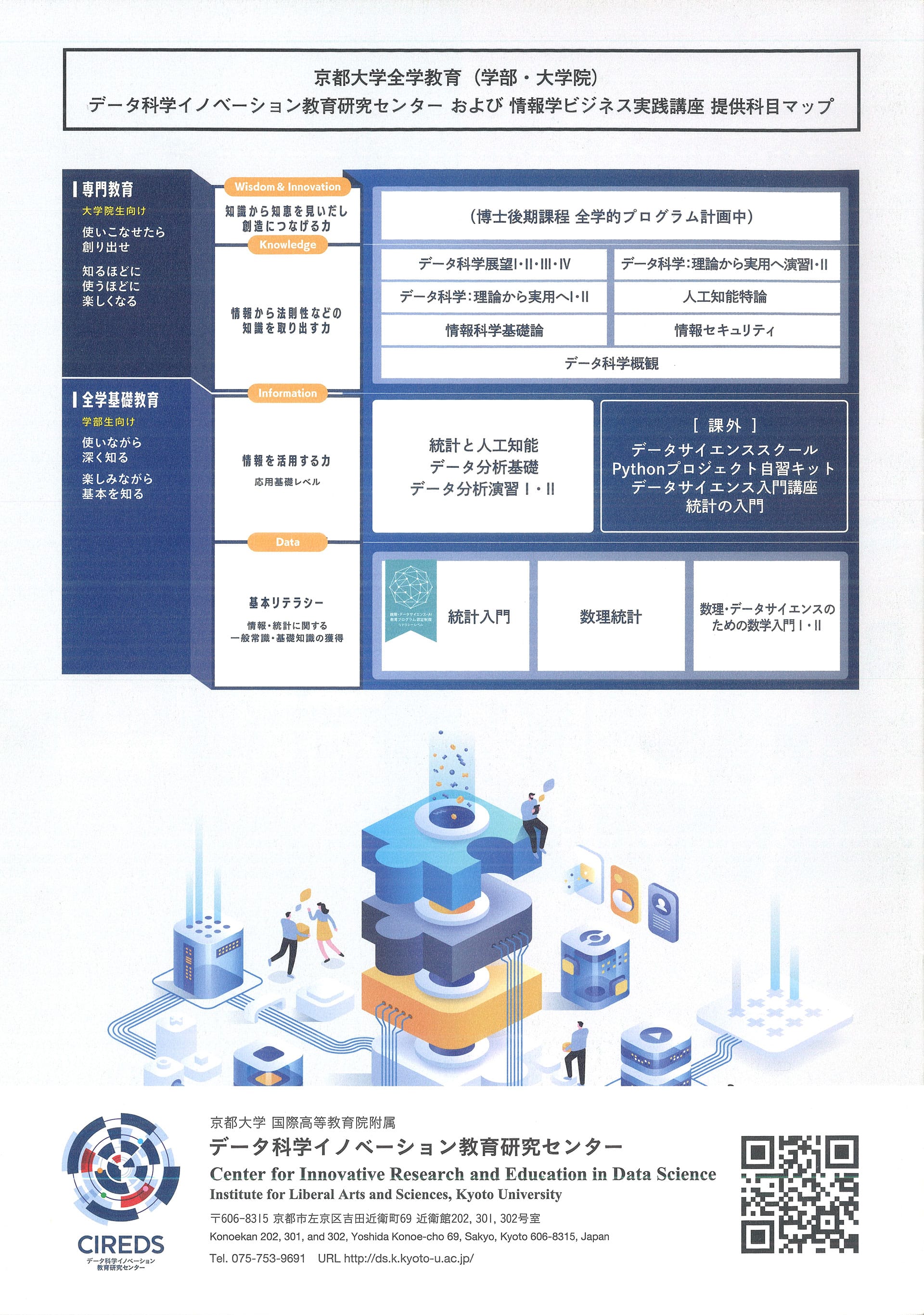
そのうちの1校として定められた京都大学は、国際高等教育院に附属データ科学イノベーション教育研究センターを設立し、人工知能やビッグデータといったデータサイエンスの基礎を学生に教えるべく、情報学・統計学・数学をバランスよく融合した科目の設計、およびカリキュラムの整備を行っています。
今回は田村寛氏、林和則氏、植嶋大晃氏に、文字起こし業者を活用した教材の作成や、教育現場におけるAIツールの活用方法などについて、当社代表取締役 田邊よりお話を伺いました。

京都大学国際高等教育院附属データ科学イノベーション教育研究センター特定教授(2017年~)を経て同教授(2021年~)。主な研究分野は「画像情報や遺伝情報も含む臨床データを活用した疫学研究」、「ナショナル・データ・ベース(NDB)を含むレセプトデータやEHRシステムを活用した疫学研究」、「病院経営改善を指向した病院情報システムの改善、新システムの実装や情報の利活用に関する研究」など。

京都大学国際高等教育院附属データ科学イノベーション教育研究センター 教授(2020年~)。主に物理・工学などのさまざまなシステムに現れる諸問題に対する数理モデルの構成法と解析、および実際的な応用に必要となる有効なアルゴリズムについて、確率・統計的なアプローチによる研究を行っている。

京都大学国際高等教育院附属データ科学イノベーション教育研究センター 特定講師(2022年~)。主な研究分野は「全国規模の介護レセプトデータ(介護DB)を用いた、介護サービスの利用実態を明らかにする研究」、「診療レセプトデータを用いた疫学研究」、「民間企業が医療データを適切に活用するための教育プログラム開発」など。

田村氏:“サイエンス”に出した記事が、まさに僕らに与えられているミッションそのものなんです。
文部科学省が「もっと日本中でデータサイエンス教育をしましょう」という方針を打ち出したことをきっかけに、京都大学は新たな試みとしてデータ科学イノベーション教育研究センターを設立し、“数理・データサイエンス・AI教育プログラム(リテラシーレベル)”を認定することになりました。具体的には全国約50万人の大学進学者を対象に、リテラシーレベルの教育をしましょうっていうことです。
単位を修得すると学生に認定証が与えられる形になっていまして、彼らの就職に有利になることが期待されています。現段階ではリテラシーと応用基礎という2段階のレベルが実装されています。
われわれ京大は、初年度に拠点校の1つに指定されたのですが、そのプロジェクトの一環として、全国で使いやすい教材を作ることも求められました。
初めにお話しした通り、この教育プログラムの意義は日本中でデータサイエンス教育をすることです。対象となるのは京大の学生のみならず、周辺大学や全国の学生たちも含まれますし、さらには2年前から企業へのリカレント教育・リニューアル教育も加わっています。
新しい試みでも人手も足りないこともあり、講義内容をそのまま教材にできないか、という発想に至ったわけです。

田村氏:コロナ禍に対面授業が制限されたことをきっかけに、動画教材も必要になりました。講義で使うスライドを整理して、動画音声をテキスト化してスライドの説明文にした教科書を作れるのではないかと考えました。
そもそも大学生向けの教科書は固いものが多く、とっつきにくい印象を持っていました。一方、高校生向けの大学受験の参考書を見てみると、予備校の授業をそのまま文字にしたような、非常に分かりやすい本があって、それが割とよく売れていたりするんですよね。実際、僕も学生時代にそういった書籍で勉強した記憶があるので、こういった類いの分かりやすい教科書が作りたいと思っていました。どこかで聞きかじったことに、日常の言語で学べる素晴らしさ、という意義もあるので、基本的には口語で、しかも可能な限り関西弁でという希望もありました。
林氏:田村先生がそのような気持ちを持っておられる中で、今回東京反訳さんの文字起こしをベースに、CIREDSの教員の総力でこのような教科書という形にできたのはよかったなと、僕は思っています。
京都大学 データ科学イノベーション教育研究センター
『講義実録 統計入門』現代図書
2023年3月31日
ISBN:978-4-434-31857-3

田村氏:データサイエンスって工学部とか理学部のイメージがあると思うんですが、いわゆる私立文系みたいなところ、例えば経済学や考古学でもデータを扱いますので、われわれが教育する学生の中にはそういった層も含まれます。
林氏:そういう意味でも、統計学の専門家ではない僕らとしては、入り口を広げなくちゃならないという使命感を持っています。特に統計学の分野では、厳密さよりも分かりやすさを重視した教科書が少ないことが問題だと思っています。数学的な厳密さを突き詰めようとして、結局何を言っているのかよく分からない、定義と証明だらけの教科書になってしまっては意味がないし、バランスが重要かなと思っています。
田村氏:そう考えた時に、自分たちがしゃべっている言葉をそのままテキストにする、いわゆる口語調のテキストを作りたいという話になったのですが、いざ出版社で「口語調の本を出したい」と話しても、あんまり響いている感触が得られなくて……。出版社探しに苦心していた頃に、「口語調で教科書を作るんだったら、いっそのこと文字起こしの専門会社に頼めばいいのでは?」といった具合に話がまとまり始めて、それで今回の依頼に至ったという経緯があります。
実際に依頼してみると、精度の高い文字起こし原稿がすぐに納品されたので大変助かりました。
林氏:特に企業へ教育内容の説明を行う際には、締め切り厳守で何かしらの成果物を提出したいという思惑もありましたので。一方で、各人の口癖もそのまま起こされていたので、記事にする際には自分たちで手を加える必要があり、そのあたりは少し苦労しました。
林氏:今回のように教材を外部に発注するにあたって、文字起こしはA社、スライドの改造はB社、出版はC社……というふうに、作業を一個一個分解しないといけないところがあるのですが、そうなると自分がプロジェクトマネジャー的な役割を担って、いろいろと管理しないといけなくて。でもわれわれとしてはその作業が苦手な領域というか、非常に手間がかかるというのが正直なところで、他の大学の皆さんはどういうふうに業者を活用されているんだろう、というのは気になるところでもあります。
代表田邊:他の大学さまの文字起こしの活用事例としては、講義やインタビューが多いですね。特に看護学科のインタビューは定性調査の研究に使われています。
林氏:なるほど。他に文字起こしというと、大学教員にとってネックになっているところは会議の議事録ですかね。学内や学会の会議で、結構たくさんの議事録を作る必要があるんですけど、特に若手の研究者は研究会の運営等で忙しくて、なかなか手が回らないっていうのが正直なところじゃないかと思うんですよね。だからこそちょっとでもお金を出して、外注することもできるんだよって示してあげると、忙しさがだいぶ緩和できるんじゃないかと。
代表田邊:ありがとうございます。その他、機関紙やウェブ公開記事などのご注文もよく頂いてまして、研究会で討論されたり、座談会されたりした内容をそのまま起こして記事にする、といったご依頼もあります。
植嶋氏:確かに写真を撮っておけばインタビュー記事が作れますね。
代表田邊:とにかく文字にさえなっていれば、その後の処理が何かと楽なんですよね。
林氏:報告書を作るのも非常に楽になりますよね。動画だと後から見返すのが面倒くさいですし……なるほど。
東京反訳では講義やインタビュー、会議の文字起こしの他に、翻訳、字幕挿入、データ入力などのご依頼も承っております。科研費の書類、特殊フォーマットへの対応などもお気軽にご相談ください。

代表田邊:近頃はAIを活用される研究者さまも増えていますが、今後どんどん使っていきたいとか、逆にちょっと苦戦されているとか、そういうご経験はおありだったりしますか?
林氏:例えばYouTubeに動画を上げると、勝手に文字にしてくれたり、他言語に翻訳してくれたりするじゃないですか。だけど、今のところは最終的に人の目で確認する必要がありますし、結局その確認作業に時間を取ることになりますよね。YouTubeでツールの使い方を勉強して、まねしてみたりもしたんですけど、やっぱり慣れないし、苦労した挙げ句にできた原稿も、正直そのまんまでは使えないみたいな、そういうのがあるんですが。植嶋先生は、もうちょっと効率的にされてたりしますか?
植嶋氏:まだ試行ですが、自分の講義動画をYouTubeに非公開でアップロードして、自動で付く字幕をコピーしたもの――この時点では句読点がなく、ただひたすらに文字が並んでいるんですが――これをChatGPTに「一言一句違わず句読点だけを付けてください」と指示してみたりしていますね。それを最後に私が見て、自分なりのアレンジを加えて原稿を作る、というような方法です。ただ、やっぱり「あー」とか「えー」とか、原稿に不要な発言も全て文字に起こされるので、そういう※ケバを削っていく作業の負担が大きいですね。
ケバとは:会話などに含まれている、それ自体では意味をなさない短い言葉のこと。ケバをそのまま文字に起こすと原稿が読みづらくなるため、東京反訳の「標準起こし」では追加料金なしでケバを削除しています。
あと、文字起こしが関西弁にちょっと弱い印象があって……私、緊張すればするほど関西弁になるので、意味の通らない文字起こしになっていることもあります。
代表田邊:確かに、AI音声認識は方言対応の精度が落ちる傾向があります。関西弁はまだいい方で、例えば日本人が話す英語など、イントネーションが少し異なる発音はきちんと認識されない等、認識率が悪化することがあります。
植嶋氏:結局、まだまだ人間が確認作業で苦労しているところが大きいので、そのあたりこそプロにお願いして、もうちょっと楽にできないか……というのは思いますね。
また、自分の講義であれば全く問題ないと思いますが、ものによってはYouTubeに上げていいのかとか、ChatGPTの学習に使われると困るとか、規約などの面で不安があるので、そのあたりの対応も含めてセキュリティーがしっかりされている会社に丸ごとお願いしたいというのが本音です。
田村氏:研究の合間にツールの使い方を調べて、試して、さらには検証までしなあかんとなると……「もうええわ!」という気になってきますね。
植嶋氏:今、話していて思ったのは、せっかく人手でご対応をいただけるなら、AI音声認識の文字起こしを行った後の、その先のところまでご提案いただけたらすごくいいのかもしれないと思いました。例えば今回みたいな書籍化を前提とした文字起こしなら、「語尾を統一してみるのはどうですか?」という提案がある、とかですね。
そのためには継続的に関わっていただいて、その学会の分野とか、研究者のキャラクターとか、そういうものも含めて文字起こししてくださったら、業界用語にも慣れていくし、こちらが確認することも減るので、すごく楽になりますね。

代表田邊:われわれとしてもこの先AIがどこまで進化していくのか、気になるところではあるのですが、将来的にAIに分かりやすい教科書を作ってもらう、みたいなことってできるようになるんでしょうか。
田村氏:AIは平均的なことには非常に強い、という印象を持っています。そのためいろいろなデータをもとに、広く浅く使われる教科書を作ることは割とできるんじゃないかと思います。ただ、個別対応が必要になる研究の指導などは、人でないと当面難しいんじゃないかと思っています。
林氏:インターネットでたくさん情報が出ている、例えば固有名詞とかはすぐに答えられるけれど、情報の少ない人名について質問すると、平気でうそをついてきたりしますからね。相手の気持ちは理解しておらず、確からしさ何%という次元で動いている。
でも、まず平均を教えるっていう意味では、AIは非常に優れた指導者なので、使えるところはどんどん使っていいと思っています。例えば偉い人に宛てて英語で手紙を書く作業は、自分でやろうとすると割と面倒くさい仕事ですけれど、取りあえず一度AIに書いてもらうとかなり負担が軽減されますよね。今の学生はLINEとかしか使わないから、メールってどんなふうに書けばいいのかよく分かっていないんですけど、取りあえず一回AIに書いてもらうと、メールってこう書くのねっていうのがすんなり理解できる。
一応最低限の使用規定は設けていますが、京大では基本的にはAIを積極的に利用して、何に使えるかは自分で考えなさい、という方針で教育しています。この先の将来はむしろ、AIを有効に使える人が社会に出て行った方がいいと思っているんです。
人にしかできないことは人に、AIが得意とすることはAIに。それぞれをうまく活用することで、結果的に日本の研究欲の向上につながっていったらハッピーですよね。
公開日:2023.10.31