「“音声認識を使って効率的にテープ起こしをする”をテーマに、現在の代表的な音声認識ソフトやサービス、テープ起こしをする際におすすめのもの、音声認識を使ってテープ起こしを効率的にする方法などについて、まとめる」
(1)いろいろとある音声認識ソフトやサービス。代表的なものと、その特徴
(2)テープ起こしにはどれがおすすめ? 仕事編
(2-a)ドラゴンスピーチ11、AmiVoice SP2などの特徴と、その比較
(3)テープ起こしにはどれがおすすめ? その他
(4)音声認識を使ってテープ起こしを効率的にする方法とは
(1)~(3)では代表的・おすすめの音声認識ソフトやサービスについて紹介してきたが、この(4)では実際に音声認識を使ってテープ起こしをする方法や効率的にするコツなどについてまとめてみたい。音声の文字化についてだけでなく原稿の最終チェックや用事用語の統一などについても触れる。
■音声認識を使ってテープ起こしをする方法
音声認識を使ってテープ起こしをする場合、方法としては次の2通りがある。
[1]録音音声を自動的に文字化する(録音音声の自動文字化)
[2]録音音声を聞きながら復唱することで文字化する(リスピーク)
[1]の方法でうまく文字化できればそれに越したことはないので、気になる場合はまず音声認識を使って録音音声の自動文字化を試してみるといいだろう。
ただ、現状として自動的に文字化はできても高精度で起こせるかどうかは音声によるので、まず[1]の方法を少し試してみて誤変換が多いようだったら[2]のリスピークでテープ起こしをしたほうが効率的だ。誤変換が多いと修正が大変で逆に手間がかかるので、録音音声の自動文字化を少し試してみて使えなさそうだったら、さっさと諦めて[2]の方法に切り替えるべし。
■録音音声の自動文字化についてのまとめ
不特定話者の録音音声はクラウド型の音声認識のほうがスタンドアロン型のものよりもやはり高精度で起こせる。ただし、クラウド型の音声認識を使う場合は注意点もあるので、それを踏まえた上で使うこと((2)を参照)。
クラウド型の音声認識でおすすめのものは(3)を参照のこと。中でもGoogleドキュメントは無料で使えるし精度も高いので個人的にはおすすめ。裏技としてステレオミキサーを使用すると録音音声の自動文字化も可能(PCの録音デバイス設定確認)。ステミキが搭載されていない場合は仮想ステミキを構築するといい。Macの場合もSoundflowerの導入などで環境構築可能。
テープ起こしの際にクラウド型の音声認識の使用が禁止されている場合や機密情報が含まれている音声を扱う場合はスタンドアロン型の音声認識を使う。スタンドアロン型の音声認識については(2-a)を参照のこと。
ドラゴンスピーチ11とAmiVoice SP2には録音音声の文字化機能があるが、これらスタンドアロン型の音声認識エンジンはユーザー個人を学習して成長していくものなので、基本はそれに合った音声でなければこの機能で実用レベルの結果を得るのは難しい。ただ、これらのソフトで不特定話者の録音音声の文字化を試す場合は、次の設定で試してみるといいだろう。
【AmiVoice SP2】
ユーザー:なし、辞書:標準(大)-汎用音響モデル
【ドラゴンスピーチ11】
プロファイルはそれ用に新規で作り、不特定話者の録音音声の文字化を試す場合はプロファイルを切り替えて使用することをおすすめする。自分の声を学習しているプロファイルで不特定話者の録音音声の文字化を試した場合は、プロファイルの保存はせずに終了したほうがいい。もし保存して自分のプロファイルの認識精度が悪くなってしまった場合はプロファイルの復元を検討する。
■録音音声についてのまとめ
後のテープ起こしを効率的にする最大のコツは、うまく録音をすることだ。
音声としては「発話者の口元とマイクの距離が近く、はっきりとした音声で録音されており、周囲のノイズがほとんどない状態の、音質が良いもの」であれば、基本的に高精度で自動文字化が可能。また話し方も重要で、アナウンサーのように滑舌よく語尾まではっきりと話された音声はうまく認識されやすい。
ただ、録音状態が悪かったり話者が複数いたりすると、そのままの音声では基本的にうまく音声認識で自動文字化はできない。
録音音声をどうしても音声認識によって自動かつ高精度で起こしたいという場合は、音声を聞きながら復唱している自分の声を録音し、その録音音声を自動文字化するという手もある。なお、復唱で行う場合はいったん録音しなくても音声入力でダイレクトにテープ起こしをすることも可能(次の〈2〉の方法)。
■リスピーク(復唱)で音声入力していく際のコツと方法
[1]の方法を少し試してみて誤変換が多いようだったら[2]のリスピークでテープ起こしをしてみよう。復唱というのは録音音声を聞きながら自分で同じ言葉を発声することで、「音声を聞きながらマイクに向かって復唱した言葉を音声入力で文字化する方法」をリスピークと呼んでいる。リスピークはある程度の慣れも必要だが、慣れるとキーボードで入力していくより音声認識を使うほうが楽で速く仕上がることも増えてくる。
【リスピークをうまくするコツ】
自分の発声が聞こえてしまうと聞き取りに集中できなくなるので、自分の声よりも聞き取る音声の音量を少し大きめにしておくといい。
【リスピークの方法】
録音音声を聞きながらマイクに向かって復唱することで音声入力する。その際、方法としては次の2通りになるだろう。
〈1〉復唱しつつ音声入力を確認、必要に応じて修正しながら進めていく方法
〈2〉修正などは後からまとめて行うので、音声を聞きながら復唱することに集中し、先に音声入力してしまう(あるいは復唱の声を録音して自動文字化する)方法
どちらの方法が効率的かは、好みや慣れ、音声の内容や状態による。リスピークに慣れていない場合や音声入力を初めて使う場合などは〈1〉の方法でうまく文字化できているかどうかをまずは確認しながら行ってみるといいだろう。リスピークでは音声を聞きながら同じ言葉を発声していかなければならないが、聞きづらい音声だと音の理解に時間がかかり、うまく発声できず誤変換となってしまうことも多い。そんな音声の場合や[1]の録音音声の自動文字化を行いたい場合は〈2〉の方法で音声を聞きながら復唱することだけに集中したほうが効率的だったりもする。
■リスピークに向くスタンドアロン型、そしてドラゴンスピーチ11の個人的な使い方とコツ
リスピークの場合はスタンドアロン型の音声認識の良さが生きてくる。自分の声の特徴を学習して成長していくこと、辞書をカスタマイズできること、音声コマンドやショートカットキーなど各種ユーザーに合わせた設定ができること、が主なメリットだ。
私自身はメインでドラゴンスピーチ11、サブ的にAmiVoice SP2を使っている。ドラゴンスピーチ11がメインになった理由は、学習につながる修正がしやすいことと、ボキャブラリエディタで単語管理ができること、この2点に尽きる。今はドラゴンスピーチ11を使うことによって音声認識の時点で表記の統一も大体なされた文字化ができている。
ただ、がっつり音声認識でテープ起こしをしているわけではなく、キーボードと音声認識を併用している。操作にはショートカットキー(ホットキー)を設定し、例えばマイクのオン/オフや、修正(修正ボックスの表示)などは全て基本的にショートカットキーで行っている。音声再生ソフトも同様に設定し、音声の再生/停止やタイムコード挿入なども全てショートカットキーで操作。個人的にはそのほうがテープ起こしは効率的に進められる。
リスピークの方法としては音声によって〈1〉〈2〉を使い分けるが、〈1〉の方法でやることが多いかもしれない。ドラゴンスピーチ11を立ち上げてすぐはレスポンスを見るためにも復唱しつつ変換結果を確認・修正しながら進める。安定したら“長め”に復唱に集中して音声入力する(できるだけ音声認識を意識して話す)。
都度修正していくほうが学習内容が反映され後の修正が減るメリットがあるが、そのほうが作業としては最終的には時間がかかってしまうことも多い。好みと状況次第だ。個人的にはドラゴンスピーチ11の学習度合いからも今は長めの復唱で作業を進めることが多い。
長めに復唱する場合は音声入力開始時にタイムコードを挿入しておき、復唱に疲れたらマイクをオフにし、挿入したタイムコードの位置から音声を聞き直し確認・修正の作業をする、といった流れだ。修正するときは修正ボックスを使って学習させる。文字化の表記によってはボキャブラリエディタで表記をカスタマイズしながら進める(後述)。
ただ、短めの音声や音声の内容によっては〈2〉の方法で一気にやったほうが効率がいい場合もあるので、状況によってやり方は変える。音声の内容的にタイピングのほうが効率的だと思った場合は、音声入力はやめてタイピングで仕上げることも多い。
〈1〉方法でやるときは、マイクのオン/オフは頻繁に切り替えながら使っている。マイクがオンになっているとドラゴンスピーチ11は常に認識しようと頑張っている。それで認識以外の別の操作を挟むと認識できず考え込んでしまうので、レスポンスが悪くなってしまうからだ。認識以外の別の操作を挟むときはマイクはオフに切り替えたほうがスムーズに作業が進む。
認識については[ツール/オプション/表示タブ]の認識ボックス項目にある“認識中の内容を表示”をオンにしておくと、ドラゴンスピーチ11が今どういう状態なのかが把握しやすくなるので便利だ。
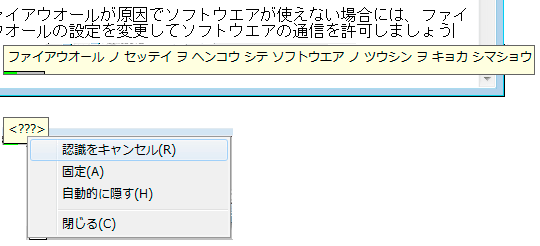 認識中の内容を表示”をオンにしておくと認識中の内容が表示されるので、ドラゴンスピーチ11が今どういう状態なのかを把握しやすい。下のイメージのように考え込んでしまって進まないときもあるが、そんなときは右クリックするとメニューが表示されるので認識をキャンセルするといい。その際、マイクはオフに切り替わる。
認識中の内容を表示”をオンにしておくと認識中の内容が表示されるので、ドラゴンスピーチ11が今どういう状態なのかを把握しやすい。下のイメージのように考え込んでしまって進まないときもあるが、そんなときは右クリックするとメニューが表示されるので認識をキャンセルするといい。その際、マイクはオフに切り替わる。
【ドラゴンスピーチ11の魅力・修正とボキャブラリエディタ】
ドラゴンスピーチ11の魅力は、学習につながる修正がしやすいことと、ボキャブラリエディタで単語管理ができることだと思う。ボキャブラリエディタは辞書のようなもので、ドラゴンスピーチ11に登録されている単語を確認したり、ユーザーが単語を追加したり、削除したりできる。ユーザーが単語を追加できるのは珍しくないが、登録単語を削除できるというのがボキャブラリエディタのポイントだ。これをうまく使うことでユーザーのほうで音声認識時の表記をカスタマイズできる。
【ボキャブラリエディタでの単語(表記)のカスタマイズ】
例えば、次の文章はドラゴンスピーチ11で実際に音声入力した結果だ。誤変換もなく、問題なく音声入力できている。

ただ、例えば共同通信社の『記者ハンドブック』に準拠した原稿に仕上げたい場合、この文章は表記を修正し「ファイアウォール→ファイアウオール」、「ソフトウェア→ソフトウエア」としなければならないので、後からその修正の手間が生じる。面倒だ。
そこでボキャブラリエディタが活躍する。ボキャブラリエディタではドラゴンスピーチ11に登録されている単語を確認できるだけでなく、単語の追加や削除もできる。例えばその表記ボックスに「ファイアウオール」と入力してみた画面が次だ。
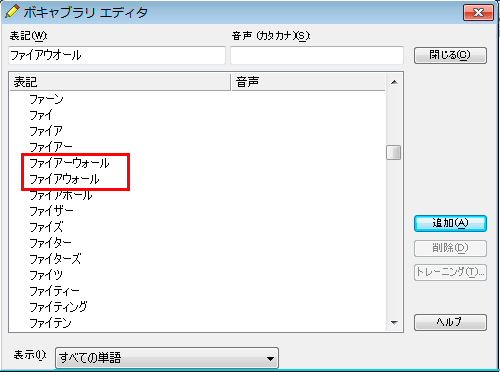
今は「ファイアウォール」、「ファイアーウォール」という表記は登録されているが、「ファイアウオール」は登録されていないことが分かる。ただ、『記者ハンドブック』に準拠した表記にしたい場合、「ファイアウオール」という表記が必要で、今登録されているこの2つの表記は不要だ。
そのような場合、ボキャブラリエディタでは登録されている単語(表記)を削除できるので、この2つの表記を削除する。代わりに「ファイアウオール」という表記を新しく追加する。
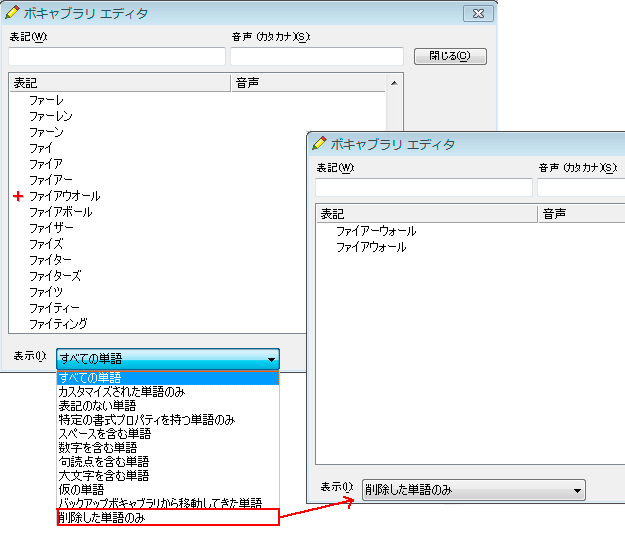 ユーザーが追加した表記には赤の+が付く。下のプルダウンメニューからは表示を切り替えられる。
ユーザーが追加した表記には赤の+が付く。下のプルダウンメニューからは表示を切り替えられる。
ユーザーが表記を追加すると、その表記には赤の+が付く。追加した単語の一覧は下のプルダウンより「カスタマイズされた単語のみ」を選択すると確認できる。「削除した単語のみ」を選択すると、削除した表記のみを確認できる。
なお、ここでの削除は完全に削除されるわけではなく、また戻したい場合は追加可能なので安心だ。ただ、ユーザーが追加した表記も一度登録すると完全には削除できないので注意。お試しなどで無駄に追加すると余計なゴミになってしまう。ユーザーが追加した単語のみ、不要なものは完全に削除できるようになれば、個人的にはうれしいのだが。改善を期待したい。
ということで、同様に「ソフトウエア」も処理して、再度同じ文章を音声入力した結果が次の下の文章だ。音声入力の時点で表記を「ファイアウオール」、「ソフトウエア」とすることができた。

このようにボキャブラリエディタで単語(表記)をカスタマイズすることで、音声入力時点での表記の統一が可能となる。このカスタマイズの内容は現在のプロファイルに保存される。いろいろと表記の追加・削除を試してみたい場合は、プロファイルを切り替えるかボキャブラリのバックアップを取ろう。
ただし、この反映について過度な期待はしないこと。そのときの認識のされ方により期待した結果とならない場合もある。そこが音声認識開発の難しいところでもある。うまく反映されない場合はトレーニングで音声をひもづけてみるといい。カスタマイズすると後の作業が楽になることは確かだ。
なお、今紹介したボキャブラリエディタの使い方は、あくまでも個人的な使い方なので、あしからず。今まで他の記事などでもこのような使い方の紹介は見たことがないが、他のユーザーの使い方が気になるところだ。
【修正ボックスを使った修正時のポイント】
ドラゴンスピーチ11のもう一つの魅力としては学習につながる修正のしやすさがあるが、修正ボックスを使って修正していくことで表記なども例えば「iot →IoT」といったように学習させていくことが可能だ(ツール/オプション/修正タブの設定にもよる)。
なお、ドラゴンスピーチ11ではユーザー側で修正範囲を選択して修正できるが、修正ボックスを使って“文章単位で修正する”ときは、どう音声がひもづけられているのかも確認してみよう。
1つの文章でも音声は区切って認識されており(区間検出)、例えばAmiVoice SP2ではその区切りがエディタ上で分かるようになっている。ドラゴンスピーチ11ではその区切りが目視はできないが、修正ボックスの“再生”でその範囲にひもづけられた音声を聞くことが可能だ。
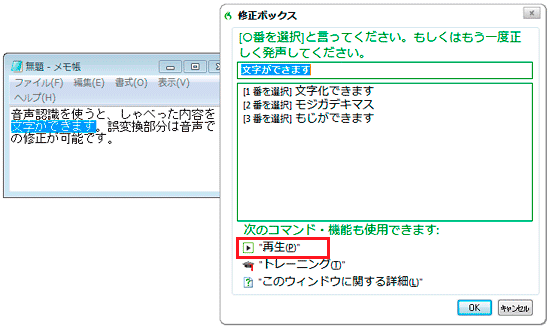 修正ボックスの“再生”でひもづけられた音声を聞くことができる。ひもづけられた音声がない場合や区間検出と一致しなくて再生できないときはグレー表示となる。
修正ボックスの“再生”でひもづけられた音声を聞くことができる。ひもづけられた音声がない場合や区間検出と一致しなくて再生できないときはグレー表示となる。
修正ボックスでの修正は、この音声に正しい語句をうまくひもづけ、それを学習させていく作業なので、ユーザー側がそれを意識して修正してあげることでうまく学習させていくことができる。特に文章単位で修正する際は、音声の区間検出も意識して修正範囲の選択などを行うといい(とはいえ、修正の範囲選択で区間検出を意識しすぎる必要はない)。
ドラゴンスピーチ11を使う場合はボキャブラリエディタと修正をうまく使っていくことがコツの一つだ。その作業が今後の効率アップにつながっていく。
■その他のコツやチェックポイント
音声認識を使用してテープ起こしをした場合、自分でタイピングしたときよりも誤字脱字に気付きにくいので注意。最終的に用事用語の統一や「てにをは」抜けなど文章としておかしい部分をチェックするときなどは例えばワードの校正機能等を活用すると便利。
設定やソフトにもよるが、音声認識の際に不要な半角スペースが挿入される場合も多いので、最後に検索し、あったら削除。
音声認識をがっつり使っていくなら必要に応じて音声コマンドを自作するのも効率化に有効(自作できるソフトに限る)。
ドラゴンスピーチ11で音響モデルの最適化やプロファイルの保存を行ったときなどに認識精度が悪くなってしまった場合は、プロファイルの復元を検討する。必要に応じてプロファイルやボキャブラリのバックアップを取る。
なお、古い記事ではあるが「ドラゴンスピーチ11」の認識率を高めるポイントもよろしければどうぞ。
■最後に
音声認識を使うことで録音音声が自動かつ高精度で文字化できればうれしい限りだが、現状としてはそれが可能なのはまだ一部の音声に限られ、多くはリスピークで対応していくことになる。
リスピークという方法は余計手間がかかっているようにも見えるが、慣れるとやり方次第でタイピングより音声認識を使うほうが楽で速く仕上がることもある。スタンドアロン型の音声認識は使い込むほど自分仕様になっていくのも魅力だ。
タイピングだけだとスピードの限界と体力的な疲れはどうしてもあるが、音声認識をうまく使っていくことでスピードアップと疲れの軽減が期待できる。要はツールなので使い方次第だ。音声認識で効率的に起こすには慣れも時間もある程度は必要で初めは使えないと感じるかもしれないが、良いパートナーになる可能性は十分にある。