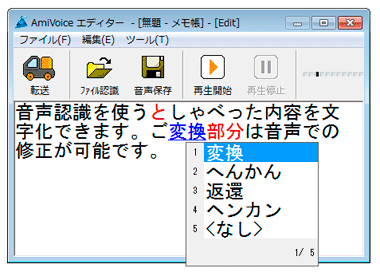
テープ起こしは、録音された音声を聞きながらそれを文字化(テキスト変換)する作業あるいは仕事で、「音声起こし」、「文字起こし」、「書き起こし」と呼ばれることもある。
録音の内容を文字化したいと思っても、手書きであれ、タイピングであれ、それを全て手作業で行うのはとても大変。何とか楽にテープ起こし(音声の文字化)ができないものかと考える人は多いだろう。
この悩みを解決する可能性を秘めたツールの一つが音声認識だ。ちなみに、音声認識とは人間の声などをコンピューターに認識させること。現在はさまざまな音声認識ソフトやサービスがあり、「音声入力」や「録音音声の文字化」を行うことができる。
「録音音声の文字化」というと、自動的にコンピューターが録音の内容を起こしてくれるの?! と期待するかもしれない。ただ、この機能、現状では音声を選ばないと使い物にならないというのが正直な感想。とはいえ、一部の音声はうまく起こせるので、使い方次第だ。
「音声入力」は、代表的なもののどれを使っても現在その精度に極端な差はなく、実用的だ。ただ、各ソフトやサービスには特徴があり使い勝手も異なるので、自分の目的や好みに合ったものを選びたいところ。
ここでは“音声認識を使ってテープ起こしを効率的にする”をテーマに、現在の代表的な音声認識ソフトやサービス、テープ起こしをする際におすすめのもの、音声認識を使ってテープ起こしを効率的にする方法などについて、まとめてみたい。
【 コンテンツ 】
(1)いろいろとある音声認識ソフトやサービス。代表的なものと、その特徴
(2)テープ起こしにはどれがおすすめ? 仕事編
→次回に続く
【 関連過去記事 】
2013/01/18 ≫音声認識で楽にテープ起こしをする方法とは
2015/12/01 ≫気になる音声認識ソフト/サービスの音声認識精度等の現況、最新レポート(1)
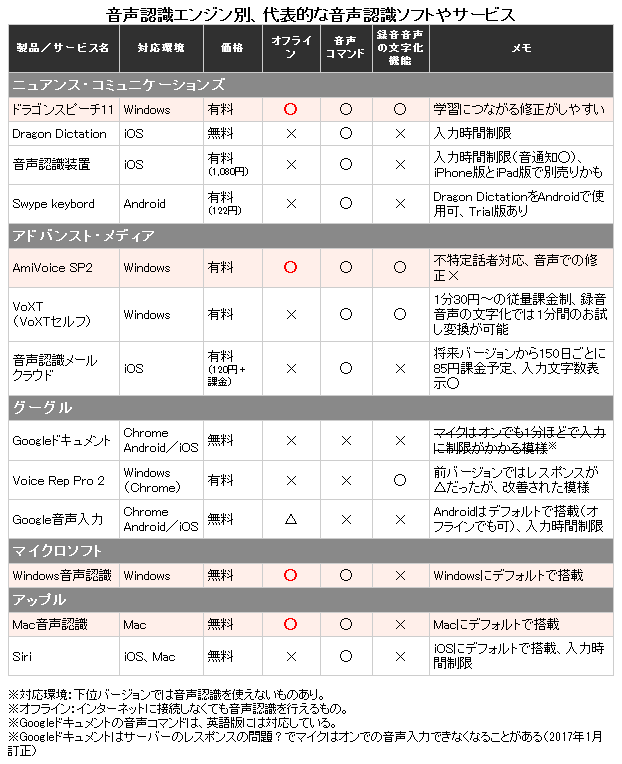
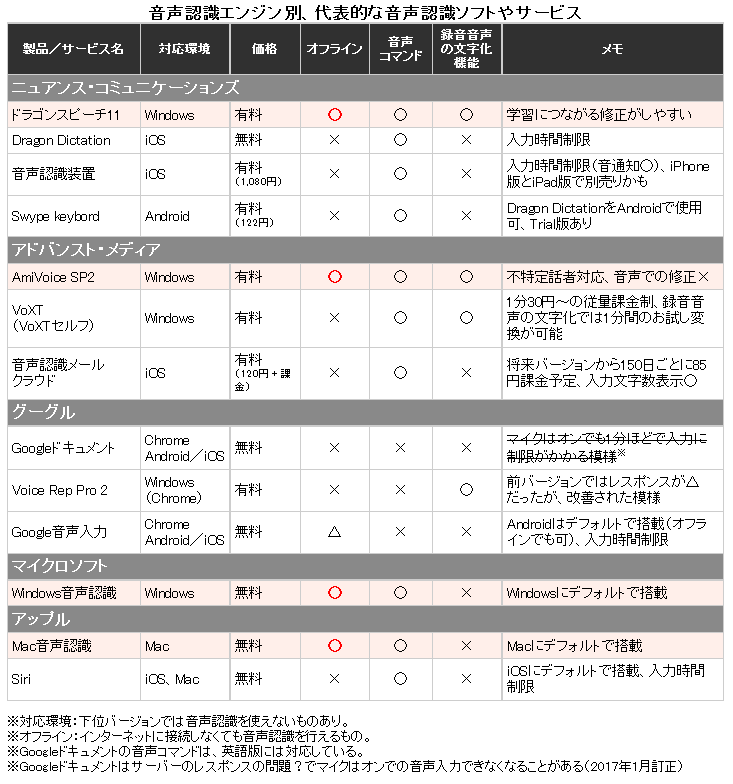
今はさまざまな音声認識ソフト/アプリ/サービスがあるが、音声認識の開発も進めるニュアンス・コミュニケーションズ、アドバンスト・メディア、グーグル、マイクロソフト、アップルなどの音声認識は、認識のされ方や精度に多少の違いはあれども実用的。代表的なものと、その特徴を次にまとめる。
仕事で音声認識を使ってテープ起こしをしたいという場合、その音声は機密情報を含んだものであることも多い。例えば個人的に仕事で使えるものを探しているという場合などは、どのソフトやサービスを使うのかよく吟味すべきだ。
おすすめは、オフライン(インターネット未接続)の状態で音声認識を行えるスタンドアロン型の音声認識だ。
■スタンドアロン型の音声認識をおすすめする理由
現在さまざまな音声認識ソフトやサービスがあるが、タイプとして大きく「スタンドアロン型」と「クラウド型」に分けることができる。
スタンドアロン型の音声認識は、オフライン(インターネット未接続)の状態で音声認識を使用可能。インターネットを介さずコンピューター単独で音声認識の処理ができる。また、ソフトの設定などを自分が使いやすいようにカスタマイズしていけるのも特徴だ。
一方、クラウド型の音声認識は、クラウド上のサーバーで音声認識の処理を行う仕組みのため、音声認識を行うにはインターネットへの接続が必要だ。
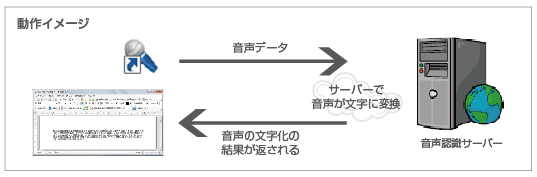 【クラウド型の音声認識サービスの動作イメージ】音声データ(しゃべった内容や録音の内容)はインターネットを介してクラウド上の音声認識サーバー(事業者側のシステム)に送られ、そのサーバーで音声認識処理が行われる。そして、その結果のテキストデータをユーザーに返す、という仕組みだ。
【クラウド型の音声認識サービスの動作イメージ】音声データ(しゃべった内容や録音の内容)はインターネットを介してクラウド上の音声認識サーバー(事業者側のシステム)に送られ、そのサーバーで音声認識処理が行われる。そして、その結果のテキストデータをユーザーに返す、という仕組みだ。
クラウド型の音声認識は、不特定話者に対応し、音声認識エンジンは多くの人の声や話し方などを学習しながら進化していくのが特徴。最近ではディープラーニング技術の導入等により精度の向上が実現しており、現在はさらなる成長が期待されている。
ただし、クラウド型のサービスは魅力的ではあるが、その仕組み上、ユーザーは音声などの情報をサービス事業者に渡すことは避けられない。特に機密情報を含む音声を扱う場合は注意が必要だ。
そのため、例えばグーグルの音声認識エンジンを採用している音声認識ソフトの「Voice Rep Pro 2」では、注意事項として次の内容が記載されている。
音声認識のために、音声データがインターネットを介してデータが送受信されます。機密情報を含む音声のご利用はお控えいただきますようお願い申し上げます。
〈引用 – ボイステクノ 〉
また、テープ起こし専門の会社では守秘義務、機密保持のため、実際にリライターに対してクラウド型の音声認識の利用を禁止しているところもある。例えば東京反訳ではリライターに対してクラウド型の音声認識の利用禁止を徹底している。
クラウド型のサービスを利用する上での懸念点は、サービス事業者に情報を渡すことになるのだが、その渡ったデータがどのような形に処理されてどう保管されているのかなどについて、ユーザーが知ることはできないということだ。また万が一、自分あるいは自社や顧客に関わる情報がそこから漏えいしてしまったとしても、自分たちでは対処のしようがない。
このご時世、クラウド型のサービスを利用していかざるを得ないところもあるが、インターネットを介したサービスに情報漏えいのリスクがあるのは事実なので、音声認識に限らずクラウド型のサービスを利用する場合は利用するサービス事業者の情報管理体制、情報管理ポリシーや利用規約などをよく確認し、信頼できるサービスを選ぶことが重要だ。
以上より、ユーザーはどのソフトやサービスを使うのかをよく吟味すべきだが、仕事で使える音声認識を探している場合は基本的にオフライン(スタンドアロン)で音声認識が使えるものをおすすめする。
【関連過去記事】
2014/03/18 ≫クラウド型音声認識サービスにおける情報漏えいリスクについて考える
■オフライン(スタンドアロン)で音声認識が使えるものでは、どれがおすすめ? その機能や特徴のまとめ
(1)の表からオフラインで音声認識が使えるものをピックアップし、精度や作業効率に関わる機能などの特徴について、次にまとめた。
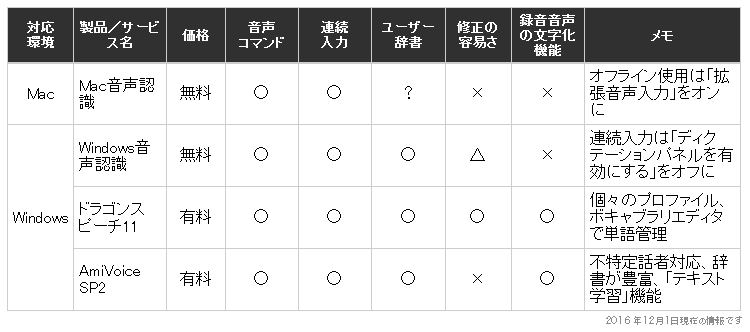
Mac音声認識、Windows音声認識は、OSにデフォルトで搭載されている音声認識だ。コストを抑えたいなら、まずはこれを一度試してみる価値はある。録音音声の文字化機能は備わっていないが、例えば仮想ステレオミキサーなどを駆使することで、録音音声を認識させることも可能と思う(余力があればまた取り上げたい)。
Windows環境に限定されるが、有料でもよければやはりドラゴンスピーチ11とAmiVoice SP2はおすすめだ。ドラゴンスピーチ11は特定話者、AmiVoice SP2は不特定話者に対応という違いはあるが、音声入力の精度は基本的にどちらもおすすめ。録音音声の文字化については、どんな音声も扱いたいということであればAmiVoice SP2のほうが将来性はあるが、現状ではどちらも一部の音声に対してしか使い物にならない。
ドラゴンスピーチ11は修正やカスタマイズの面などでAmiVoice SP2より使い勝手がよくおすすめだが、動作はAmiVoice SP2のほうが軽い。また、AmiVoice SP2は定期的なアップデートモジュールの提供もあり魅力だ。ただ、AmiVoice SP2で残念なのは修正の面。修正がしづらく学習につながらないことも多いので、ユーザー辞書の容量が増えがちだ。やみくもに単語を増やすと逆に精度が悪くなる恐れもなくはないので、そこが悩ましいところである。
次回は、これら音声認識の特徴についてもう少し詳しく紹介するほか、音声認識を使ってテープ起こしを効率的にする方法などについて取り上げる。
次回に続く