「ドラゴンスピーチを使っていく上で感じた認識率を高めるポイントやコツ、また録音データの文字化におけるポイントなどについて紹介する」
今回は「ドラゴンスピーチ11 日本語版」について、調べたり検証したりした中で感じた音声の認識率を高めるポイントをご紹介したいと思う。状況によっていろいろと変わると思うが、よければ参考にしてほしい。
【プロファイルについて】
前回プロフィルについて少し触れたが、プロファイルとは声質、文章スタイルの特徴、使用する音声デバイスの情報、トレーニングの情報などを記録した一連のファイルで、ドラゴンスピーチはそれらの情報を音声の認識に役立てている。
■まず、ヘッドセットマイク利用時はトレーニングをスキップできるが、認識精度を求めるならトレーニングは行った方がよい。
トレーニングの仕組みは、文章と音声を照らし合わせ、話者の声の高さ・トーン・癖等を学習させるというもの。そのため、トレーニングの読み上げテキストは任意の決められた文章でなければならない。声の登録は一人のみだが、プロファイルは環境に合わせて複数作成し、切り分けて使うことができる。
■最初の話者登録でドラゴンスピーチはその話者の癖を学習するので、一人の声の場合でも話し方や環境などが大きく変わる場合は、プロファイル自体を変えてしまった方が認識精度の安定につながる。
※例えば、家などで話す小声用、デモ等で話す大声用とプロファイルを切り分けて使ったり、家など静かな環境用、職場など多少雑音が多い環境用と切り分けて使ったりすることで、より認識されやすくなるようだ。
■マイクを変える場合も、マイクごとにプロファイルを作ると認識精度が安定しやすくなる。「使用中のプロファイルに音声機器を追加」により現在使用中のプロフィルに追加することも可能。学習環境はそのままで音声機器の情報を追加できる。
■定期的に「音響・言語モデルの最適化」を行うとよい。蓄積された声の特徴や言語などを解析し、ユーザファイルに登録・更新してくれるため、認識精度が向上するようだ。状況により時間がかかるので実行の際には注意したいが、スケジュール設定も可能なので、うまく利用したい。
【マイク等について】
■付属のヘッドセット以外のマイクを使う場合は、録音機器と口元の距離を一定に保つことができ、一方向からの音声のみを拾うことが可能な指向性の狭いタイプが適している。また、USB接続のものはノイズが入りにくいようだ。口元の距離は5?10センチを保てるようにするとよい。
■録音する際にも、音がきちんと拾えるようにICレコーダーと口元の距離は5?10センチを保てるようにするとよい。また、BGMなどを含む雑音が入らないように注意したい。
【ドラゴンスピーチの設定等について】
■オプションの「その他」タブ内にある「速度vs精度」のスライダーによって、速度重視か精度重視かを設定できる。普段の音声入力ではあまり意識することはないと感じるが、状況に応じて調整するとよいだろう。
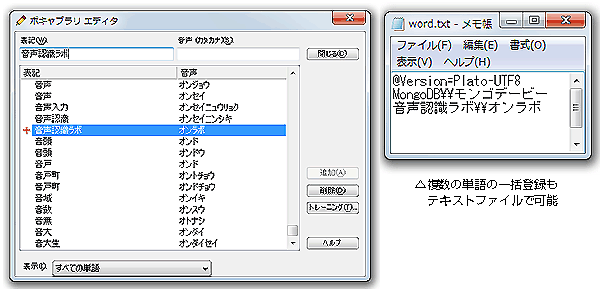
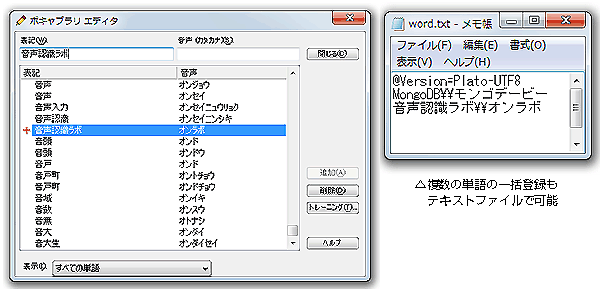
■うまく認識されない言葉は、あらかじめボキャブラリに登録しておけば認識されるようになる。専門用語など特殊な言葉が出てくる場合は先に単語を登録しておくといいだろう。複数の単語の一括登録もテキストファイルで可能だ。
※ボキャブラリエディタもうまく活用したい。ボキャブラリエディタでは辞書に登録されている単語を検索できる(ユーザが登録した単語は左に赤い+が表示されている)が、辞書に登録されているのにうまく認識されない場合もある。それは、登録されている音声と発音が違うからだ。必要に応じて音声をトレーニングしてやればいい。
※ボキャブラリへの登録は、単語だけでなくセンテンスやフレーズをあたかも一つの単語のように登録してしまうのもコツ。例えば「音声認識ラボ」の音声を「オンラボ」と登録すれば、「おんらぼ」と言うだけで「音声認識ラボ」と入力されるようにもできる。
※注意点として、特別なボキャブラリが多過ぎると音声入力の際に単語の追跡が難しくなるということ、また、新しいボキャブラリを作成するたびにハードの領域が使用されるということがヘルプに記載されている。この点は留意してほしい。
■話した言葉が誤認識される場合は、修正ボックス等を使って修正することでドラゴンスピーチが学習し、次から認識されやすくなる。オプションの「修正」タブでは、修正に関するいろいろな設定が可能だ。
【録音データの文字化について】
録音音声の認識率は、やはり録音時に決まるといっていいだろう。いろいろと試してみたが、ドラゴンスピーチのプロファイルがどうというよりも前に、録音データの質が悪い場合、その音声の文字化は基本的にまったく使いものにならない。逆に、良質の録音データを作ることができれば、最適なプロファイルでなくても認識はされやすくなるようだ。
■まずは、録音データの音質を上げること。録音データの音質の良し悪しで認識精度は非常に変わってきてしまう。
※上にも記載したが、音がきちんと拾えるようにICレコーダーと口元の距離は5?10センチを保てるようにするとよい。また、雑音などにも特に注意し、良質な録音データを作成したい。その上で話者としては話す速度や話し方に注意すると、かなり認識されやすくなる。試してみても、これらの点がクリアできないと認識結果は非常に悪い。
また、ドラゴンスピーチでは仕様上、複数話者には対応していない。前回にも記載したように一番は最適なプロファイルを作成することだが、それも難しく、基本的にプロファイルに登録されたユーザの声は認識されやすいが、その他の声は誤認識が多くなる。
ただ、傾向としては録音データに最適なプロファイルでなくとも使い込んで学習されたプロファイルを使うと、認識率はまだ改善されるように思う。特に、例えばIT分野の音声ならIT分野の内容でよく学習されたプロファイル(ボキャブラリ登録も含む)を使うと、認識率は改善されるように個人的には感じる。
とはいっても、話者が増えれば増えるほど多様化するので、複数話者の文字化はやはり難しい。また、ドラゴンスピーチを学習させる手間と時間が必要だ。だが、学習していくと少しずつだが応えてくれるので、録音データの文字化については長い目で見て検証したいと思っている。
なお、余談だが、音声認識の際には自動書式設定にある「自動的に句読点を挿入する」をオンにすると句読点も自動挿入されるので便利。また、原稿等は表記の統一や誤字脱字のチェックなどの修正が必要不可欠だが、表記の統一はボキャブラリエディタを使って私は行っている。また、コマンドを使うと効率よく作業できる部分もある。ヘルプが分かりにくいので残念だが、ドラゴンスピーチには多くの機能があり、使い方次第でよいパートナーになるのではないかと感じている。