2015年12月14日、「VoXT(ボクスト)セルフ」の音声認識エンジンのリニューアルが実施され、認識精度が向上した、とのこと。新たにDNNという新しい技術を採用したことで、アドバンスト・メディアの調査では以前誤って認識した箇所が何%改善されたかという「誤認識改善率」が約20%という結果を記録しているようだ。
≫VoXTセルフサービスの精度が大幅に向上!音声認識エンジンがリニューアルしました(2015.12.14)
DNN(ディープニューラルネットワーク)とは、多層構造のニューラルネットワーク(人間の脳の神経回路の仕組みを模した情報処理モデル)で、DNNの採用により例えばグーグルの音声検索やSiriなども認識精度の向上を実現している。
前回(https://8089.co.jp/onsei-ninshiki/760)は「VoXT」を含めた音声認識ソフトやサービスについて音声認識精度を調査し、録音音声の文字化についてはサービス開始当時とそれほど変化はなかったとレポートしたが、その後「VoXTセルフ」の音声認識エンジンがリニューアルしたとのこと。そこで今回は、「VoXTセルフ」の認識精度は本当に向上したのか、録音音声の文字化について実際に調査した結果をレポートしたい。
■「VoXTセルフ」録音音声の文字化の結果
前回紹介した音声について、今回新たに録音音声の文字化を試した結果を紹介するので、比較してみてほしい。なお、音声自体は前回の記事にアップしているので、必要であれば前回記事を参照のこと。
|
【音声1:内容】この日、東京都内で開かれた表彰式に受賞者が出席。日本エレキテル連合は、大ブレークしたコントにならって「今年だけじゃなく来年以降も使い続けてくれなくちゃ……」「ダメよ~ダメダメ」と、コントさながらのやりとりで会場を沸かせた。 ※左:前回の文字化結果、右:音声認識エンジンリニューアル後の文字化結果 |
|
【音声2:内容】 総務省が発表した4月の東京都区部の消費者物価指数、前の年の同じ時期に比べ2.7%と大幅に上昇した。消費税増税の影響によるものだ。東京都区部の指数は、来月発表される全国各地の先行指標とされ、政府や日銀の政策判断の材料となるため、注目されていた。日銀は来年の春ごろに2%の物価上昇を達成するとしている。ただ、今回の物価上昇は、増税の影響を除くと実質的には増税前の3月と同じ水準だった。総務省は想定内の上昇としているが、日銀のシナリオに沿った上昇が今後も続くか、市場では懐疑的な見方も出ている。 ※左:前回の文字化結果、右:音声認識エンジンリニューアル後の文字化結果 |
|
【音声3:内容】 なお、この画像取り違いについて小保方さんはですね、えー、データの整理が十分ではなかった、あー、元データを確認しておればこのような取り違いというのは生じなかったというように反省しているところでございます。しかし、調査が不十分であったという点は否めませんので、ねつ造という結論をこの時点で出されたということについては不服でございますので、不服申し立てをしておる、ということでございます。以上が私からの説明でございます。 ※左:前回の文字化結果、右:音声認識エンジンリニューアル後の文字化結果 |

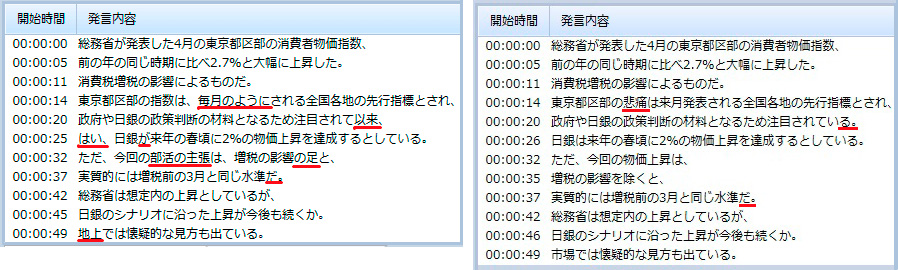
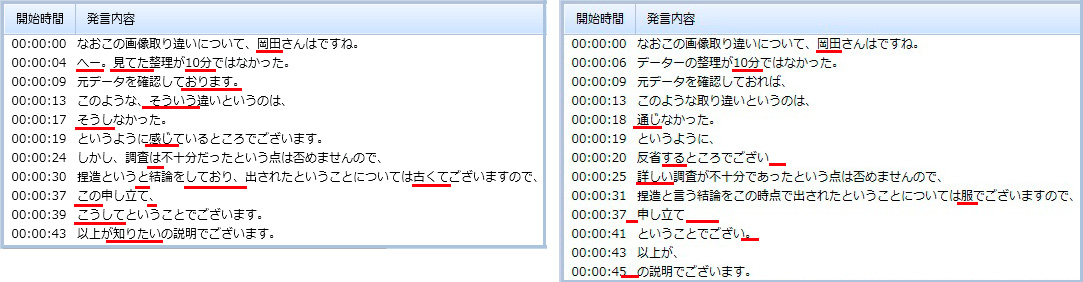
画像の赤線は誤変換部分を示している。結果を見てもらうと分かるとおり、音声1~3のどの結果においても認識精度が向上した。特に音声3は、雑音が多く、話し方も考えながら話しているためケバが多く聞きづらい音声なのだが、この文字化の結果が向上したのは、個人的に今後に期待を感じたところ。その他にもいろいろな音声を試したが、基本的に以前より認識精度の向上を実感できた。
ただ、やはり音質が悪いものは厳しく、それっぽく起こせていても内容は全然違うという結果もまだ多くあるというのが現状で、この点については、やはり人間のほうが音声認識を使って起こすということを意識したいところ。一番は、音声認識に適した音声となるよう、マイクを使って上手に音声を録音することだ。次に、話し方にも精度は左右されるので、可能であれば話者は話し方も意識したい。
【音声認識に適した音声とは・参考】VoXTセルフ 文字変換精度比較
【参考】上手な録音方法
話し方としては、アナウンサーがニュース原稿を読み上げるような淡々とした調子が認識されやすく、一定の速度である程度長い文章をしゃべるほうが認識率は上がるといえる。例えば速度は一定だが抑揚のある話し方をしている音声と、かなり早口で淡々と話している音声を音声認識させた場合、音質は同じくらいでも早口の音声のほうがうまく認識されることが多いように感じる。
例えばこちらは、速度は一定だが少し抑揚のある話し方をしている音声の文字化結果だ。
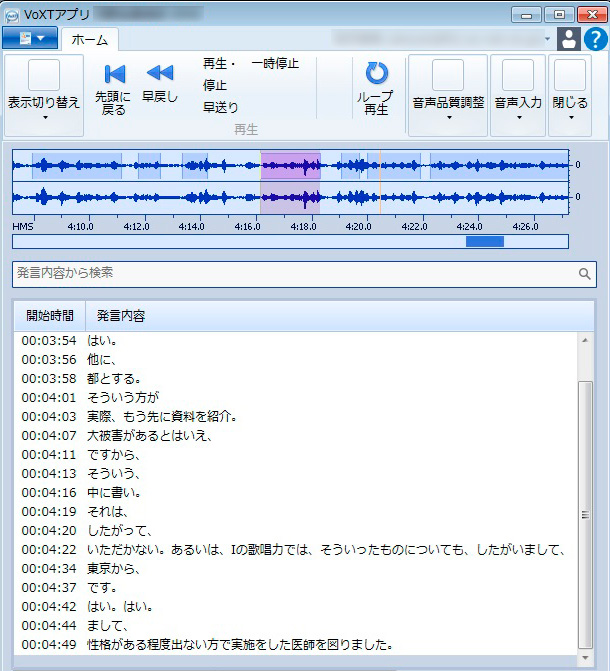
ちょっと極端な例だが、この結果を見ても分かるとおり、ほとんど内容が起こせていない。音声を聞くと、話としては途中「えー」といったケバは含まれるものの切れることなく続いているのだが、特徴として話し方に抑揚があるので、音声認識エンジンがうまく音声区間を検出することができず、細かく音声が途切れて認識されてしまったようだ。また、一部区間は音声が存在しないと判断されて、音声が検出されていない箇所もあった。
とはいえ、こちらの音声は話し方に特徴がある以外に音質もそれほどよくないので、話し方に抑揚があると駄目というわけではないので、あしからず。
結論として、録音音声の文字化については録音音声の音質、話し方、話す内容など多くのことがその精度に関わってくるのでうまく文字化できるかどうかは試してみるしかないというのが正直なところであるが、今回の音声認識エンジンのリニューアルによって基本的にその精度が向上しているのは事実といえる。
「VoXTセルフ」では指定した部分から1分間のお試し文字変換(無料)を1つの音声ファイルに対して2回まで行えるので、ぜひ有効に活用したい。今後どこまで録音音声の文字化が進化していくのか、興味深いところだ。